В материале рассматриваются нюансы и проблемы с которыми можно столкнуться если вы решаете задачу классификации с несбалансированными классами.
Одна из моих коллег недавно написала пост о том, как работать с несбалансированными классами. Она рассмотрела способы решения проблемы несбалансированного обучения, включая за и против различных подходов. Один большой вывод из статьи (которую следует прочитать) заключется в том, что нужно тщательно подумать, стоит ли решать задачу классификации оверсемплингом, или можно посмотреть альтернативы: корректировку весов классов или проверку работы модели на несбалансированных данных без изменений.
Эта статья о том, как делать кросс-валидацию, если вы решили, что оверсемплинг это верный подход к вашей задаче. Тетрадка в Github со всеми рассматриваемыми шагами может быть полезна, если вы решите поиграть с процессом самостоятельно; здесь мы выделим основные шаги.
В этой статье мы сделаем следующие шаги:
- Получим бейзлайн
- Сделаем некорректный оверсемплинг
Разобьем данные на тренировочные и тестовые, применим оверсемплинг, а потом кросс-валидацию. Звучит неплохо, но результаты получатся излишне оптимистичными. - Сделаем корректный оверсемплинг
- Ручной оверсемплинг
- С использованием конвейера `imblearn` (для тех, кто спешит — это лучшее решение)
Если кросс-валидация сделана на уже апсемплированных данных, оценка не обобщается на новые данные. В реальной задаче вы должны использовать тестовое множество только однажды; мы используем его несколько раз, чтобы показать что если сделать кросс-валидацию на уже апсемплированных данных, результат получится излишне оптимистичным и не будет обобщаться на новые данные (или тестовое множество).
Датасет
Мы будем использовать датасет связанный со щитовидной железой, в которой число плохих щитовидок составляет около 6% данных (т.е. примерно 1 из 16 пациентов имеет проблемы со щитовидкой). Нашей целью будет найти классификатор с хорошей полнотой (recall) (т.е. мы хотим, чтобы наш классификатор нашел настолько много положительных элементов, насколько это возможно). Мы хотим предупредить, что есть опасность использования этой метрики, поскольку просто предсказывая, что у каждого проблемы со щитовидкой мы получим полноту 100%.
Мы хотим быть уверены, что каждый раз работаем с одинаково разбитыми данными. Мы можем это сделать создав KFold объект, kf, и передавая cv=kf instead of the more common cv=5.
kf = KFold(n_splits=5, random_state=42, shuffle=False)1. Бейзлайн (без оверсемплинга)
Давайте построим бейзлайн с помощью случайного леса.
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=45)
rf = RandomForestClassifier(n_estimators=100, random_state=13)
cross_val_score(rf, X_train, y_train, cv=kf, scoring='recall')array([0.81081081, 0.73684211, 0.875 , 0.7037037 , 0.7804878 ])Это достойные результаты, а мы еще не оптимизировали модель! Давайте подберем гиперпараметры:
params = {
'n_estimators': [50, 100, 200],
'max_depth': [4, 6, 10, 12],
'random_state': [13]
}
grid_no_up = GridSearchCV(rf, param_grid=params, cv=kf,
scoring='recall').fit(X_train, y_train)
grid_no_up.best_score_0.7803820054409211Мы получили полноту около 78% на одной из наших моделей до того, как попробовать оверсемплинг. Давайте улучшим это значение.
Обычно мы смотрим на тестовые данные только после завершения моделирования, но здесь важно увидеть, как оверсемплинг, сделанный некорректно делает нас излишне уверенными в нашей способности делать обобщения на основе кросс-валидации. Мы еще не сделали оверсемплинг, поэтому давайте пока просто проверим, соответствуют ли результаты тестов тому, что мы ожидаем от оценок кросс-валидации (т.е. около 78%).
recall_score(y_test, grid_no_up.predict(X_test))0.8035714285714286Это вполне согласуется с результатами кросс-валидации.
2. Неправильный оверсемплинг
Давайте просто апсемплим тренировочные данные (мы достаточно умны, чтобы не апсемплить тестовые данные) и проверим, что мы получили равное разделение на два класса:
X_train_upsample, y_train_upsample = SMOTE(random_state=42).fit_sample(X_train, y_train)
y_train_upsample.mean()0.5Сейчас кросс-валидируем с помощью поиска по сетке. Отметим, что тренировочные данные были апсемиплированы и это не было частью GridSearch
params = {
'n_estimators': [50, 100, 200],
'max_depth': [4, 6, 10, 12],
'random_state': [13]
}
grid_naive_up = GridSearchCV(rf, param_grid=params, cv=kf,
scoring='recall').fit(X_train_upsample,
y_train_upsample)
grid_naive_up.best_score_0.9843160927198451Отличная полнота! Если мы посмотрим на результаты валидации они все выглядят отлично:
grid_naive_up.cv_results_['mean_test_score']array([0.93360792, 0.9345499 , 0.93337591, 0.94714925, 0.94736138,
0.94273667, 0.97585677, 0.98218414, 0.97864618, 0.98237253,
0.98187974, 0.98431609])Вот модель на которой мы получили лучший результат:
grid_naive_up.best_params_{'max_depth': 12, 'n_estimators': 200, 'random_state': 13}Ок, давайте посмотрим, как она отработает на исходных тренировочных данных (после того, как мы устраним оверсемплинг)
recall_score(y_train, grid_naive_up.predict(X_train))1.0А что с тестовыми данными?
# But wait ... uh-oh, spagetti-os!
recall_score(y_test, grid_naive_up.predict(X_test))0.9107142857142857Итак, настало время хороших и плохих новостей:
- хорошая новость: полнота на тестовых данных стала равна 91%, что лучше чем 80% которые мы получили без апсемплинга
- плохая новость: наша уверенность в результатах кросс-валдации снизилась. Без апсемплинга полнота при валидации составила 78%, что является хорошей оценкой для результата на тесте в 80%. С апсемплингом полнота на валидации составила 98%, что не является хорошей оценкой полноты на тестовых данных (91%).
3. Давайте сделаем SMOTE*-часть нашей кросс-валидации!
Проблема в том, что мы
- оверсемплим
- и только после разбиваем данные на кросс-валидационные фолды
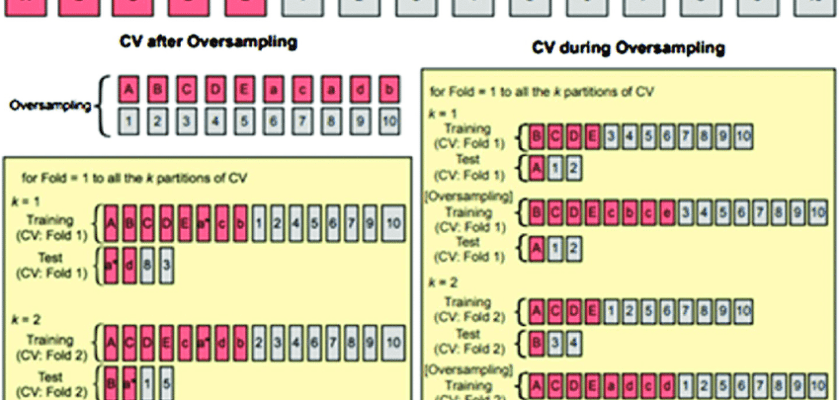
Чтобы понять, почему это является проблемой, рассмотрим простейший способ оверсемплинга (а именно, копирование элемента данных) Пусть каждый элемент меньшего класса копируется 6 раз перед тем, как сделать разбиения. Если мы делаем 3-фолдовую валидацию, каждый фолд в среднем содержит 2 копии каждого элемента! Если наш классификатор переобучится запомнив тренировочные данные, он сможет получить идеальный результат на валидационном множестве! Наша кросс-валидация выберет модель которая переобучается сильнее всего. Мы видим, что CV выбирает наиболее глубокое дерево!
Вместо этого мы должны разбить данные на тренировочный и валидационный фолды. Затем, на каждом фолде, нам нужно
- Апсемплить меньший класс
- Обучить классификатор на тренировочных данных
- Валидировать классификатор на оставшемся фолде
Давайте рассмотрим подробнее, сделав это вручную:
3A. Ручной апсемплинг в фолдах
example_params = {
'n_estimators': 100,
'max_depth': 5,
'random_state': 13
}
def score_model(model, params, cv=None):
"""
Creates folds manually, and upsamples within each fold.
Returns an array of validation (recall) scores
"""
if cv is None:
cv = KFold(n_splits=5, random_state=42)
smoter = SMOTE(random_state=42)
scores = []
for train_fold_index, val_fold_index in cv.split(X_train, y_train):
# Get the training data
X_train_fold, y_train_fold = X_train.iloc[train_fold_index], y_train[train_fold_index]
# Get the validation data
X_val_fold, y_val_fold = X_train.iloc[val_fold_index], y_train[val_fold_index]
# Upsample only the data in the training section
X_train_fold_upsample, y_train_fold_upsample = smoter.fit_resample(X_train_fold,
y_train_fold)
# Fit the model on the upsampled training data
model_obj = model(**params).fit(X_train_fold_upsample, y_train_fold_upsample)
# Score the model on the (non-upsampled) validation data
score = recall_score(y_val_fold, model_obj.predict(X_val_fold))
scores.append(score)
return np.array(scores)
# Example of the model in action
score_model(RandomForestClassifier, example_params, cv=kf)array([0.78378378, 0.76315789, 0.96875 , 0.81481481, 0.90243902])Сейчас мы даже можем сделать поиск по сетке перебрав параметры. Вспомним, что комбинации параметров, которые мы ранее пробовали были:
params{'n_estimators': [50, 100, 200],
'max_depth': [4, 6, 10, 12],
'random_state': [13]}Этот цикл перебирает все комбинации и сохраняет средний скор на валидационных данных:
score_tracker = []
for n_estimators in params['n_estimators']:
for max_depth in params['max_depth']:
example_params = {
'n_estimators': n_estimators,
'max_depth': max_depth,
'random_state': 13
}
example_params['recall'] = score_model(RandomForestClassifier,
example_params, cv=kf).mean()
score_tracker.append(example_params)
# What's the best model?
sorted(score_tracker, key=lambda x: x['recall'], reverse=True)[0]{'n_estimators': 50,
'max_depth': 4,
'random_state': 13,
'recall': 0.8486884268736002}Лучший оценщик добился значения полноты равной 85% на валидационных данных. Давайте сравним это с результатом на тесте:
rf = RandomForestClassifier(n_estimators=50, max_depth=4, random_state=13)
rf.fit(X_train_upsample, y_train_upsample)
recall_score(y_test, rf.predict(X_test))0.8392857142857143Отметим, что это примерно соответствует валидации (84% vs 85%)
3B. Использование конвейера imblearn
Библиотека несбалансированного обучения imblearn расширяет встроенные в sklearn методы конвейера. А именно, вы можете импортировать
from sklearn.pipeline import Pipeline, make_pipelineи это позволит делать несколько шагов за раз.. Также прекрасно, что если вы обучаете (fit) модель, все шаги (такие как масштабирование и моделирование) обучаются за раз. А если делаете предсказание (предикт), то шаги связанные с масштабированием только преобразуют данные и поэтому вы можете передать несколько шагов в конвейер.
Но у конвейера есть ограничение. Ограничение можно частично понять из названий функций (сравни transform с resample). Конвейер sklearn может только переобразовать одну строку в другую (возможно с другими или добавленными признаками). Делая же апсемплинг, нам нужно увеличить число строк. Imbalanced-learn обобщает конвейер, оставляя при это синтаксис и названия функций неизменными:
from imblearn.pipeline import Pipeline, make_pipelineДавайте посмотрим его в действии:
imba_pipeline = make_pipeline(SMOTE(random_state=42),
RandomForestClassifier(n_estimators=100, random_state=13))
cross_val_score(imba_pipeline, X_train, y_train, scoring='recall', cv=kf)array([0.75675676, 0.78947368, 0.90625 , 0.77777778, 0.7804878 ])Получилось намного лучше лучше нашей самописной функции! Заметим, что значения полноты похожи на те, что мы делали вручную.
Еще лучше то, что конвейеры хорошо взаимодействуют с GridSearchCV, так что нам не нужно перебирать параметры вручную:
new_params = {'randomforestclassifier__' + key: params[key] for key in params}
grid_imba = GridSearchCV(imba_pipeline, param_grid=new_params, cv=kf, scoring='recall',
return_train_score=True)
grid_imba.fit(X_train, y_train)Как видим, лучшая модель выбранная при этом поиске с конвейером совпадает с той, что мы нашли вручную:
grid_imba.best_params_{'randomforestclassifier__max_depth': 4,
'randomforestclassifier__n_estimators': 50,
'randomforestclassifier__random_state': 13}Насколько же мы хороши на валидационных данных?
grid_imba.best_score_0.8486780485230826И давайте сравним с тестовыми:
y_test_predict = grid_imba.predict(X_test)
recall_score(y_test, y_test_predict)0.8392857142857143У нас опять получилась небольшая разница, как и в случае с ручной проверкой, когда кросс-валидация дала полноту 85% (при полноте 84% на тестовой выборке).
Когда мы предсказываем, шаг SMOTE ничего не делает (просто пропуская значения на следующий шаг). Мы можем сделать это просто предсказав с randomforestclassifier, результат будет тем же:
y_test_predict = grid_imba.best_estimator_.named_steps['randomforestclassifier'].predict(X_test)
recall_score(y_test, y_test_predict)0.8392857142857143Резюме
Вот резюме различных подходов, которые мы рассмотрели:
| Method | Recall (валидация) | Recall (тест) |
|---|---|---|
| Без апсемплинга (бейзлайн) | 78.0% | 80.3% |
| Апсемплинг тренировочных данных до кросс -валидации | 100% | 91.1% |
| Апсемплинг как часть кросс-валидации (ручной) | 84.9% | 83.9% |
| Апсемплинг как часть кросс-валидации (конвейер) | 84.9% | 83.9% |
Последние две строки таблицы должны (и так оно и есть) совпадать. Разница только в конвейере которым легче управлять и с помощью которого код получается чище, но полезно один раз пощупать весь процесс самостоятельно. Высокоуровнево можно сделать следующие выводы:
- Для каждого случая кроме того, где мы делали апсемплинг до кросс-валидации, оценка на валидационных данных была согласована с оценкой на тестовых.
- Когда мы сделали апсемплинг тренировочных данных до кросс-валидации, разница в оценке между валидацией и тестом составила 9 процентных пунктов.
- При апсемплинге до кросс-валидации мы выбрали наиболее переобученную модель, поскольку апсемплинг позволяет утечь данным из валидационных фолдов в тренировочные.
- В этом примере, неправильный апсемплинг привел к лучшему значению полноты (91%). В общем это обычно не случается! Наша метрика (recall) могла быть намного хуже. Важным моментом является то, что основной способ определить, все ли у нас хорошо, — это использовать оценки кросс-валидации.
- Тестовая выборка должна быть использована только ОДИН раз. В этой статье мы использовали ее множество раз, чтобы показать как разные подходы к апсемплингу влияют на нашу возможность доверять результатам кросс-валидации.
В споих задачах вам нужно построить базовую модель, корректно апсемплированные модели и использовать результат кросс-валидации для выбора модели. Роль тестовой выборки сводится только к тому, чтобы сказать вам насколько хороша обобщающая способность выбранной модели.
Ссылки
В сети есть некоторое количество прекрасных статей; вот ссылки на те, которые мне я считаю наиболее полезными:
- An introduction to oversampling by Domino Data Lab
- The right way to oversample by Nick Becker, рассматривает опасности оверсемплинга до разбиения данных на трейн-тест. Проблема кросс-валидации не рассматривается.
- Dealing with imbalanced data: undersampling, oversampling, and proper cross-validation рассматривающая проблемы с похожими проблемами и их решение на языке R
- Cross-Validation done wrong про вопросы отбора признаков до кросс-валидации. Не совсем тема статьи, но взаимосвязь есть
*SMOTE — Synthetic Minority Oversampling Technique — Техника синтентического оверсемплинга меньшего класса.